1. 개요

지금까지는, 이름, 전화번호, 이메일 주소, 그룹을 지정할 수 있다.
이름 제외한 다른 항목들은 비워둘 수도 있다. 어떤 사람은 이름과 이메일 주소만. 있을 수도 있다.
위를 보면, 예를 들어, add 함수를 실행하고 사람 이름을 치면, 컴퓨터가 물어본다. phone ,email, group 은 뭐냐. 라고
불필요한 2개의 공백은 저장될 때 1개의 공백으로, 프로그램이 알아서 저장한다.

우리는, 입력한 정보를 directory.txt 로 저장한다.
그렇기 때문에, 파일의 형식을 살펴봐야 한다.
1) 각각의 사람에 대해 이름, 전화번호, 이메일, 그룹 등을 모두 지정해야 하는데,
어떤 사람은 1개만, 2개만 등등이 있을 수 있다.
그런데, 지금까지 전화번호부를 만들었을 때와 동일한 방식으로 저장하게 되면, 문자를 쭉 ~ 읽으면서, 어떤게 번호인지, 어떤게 이메일인지 잘 못 읽을수도 있다.
2) 또한, 이제는 이름이 한단어가 아니라, 공백이 포함되어 있다.
나중에 읽을 때, 어디까지가 이름인지, 아닌지를 판단할 수 있어야 한다.
이때 우리가 쓰는 기술은 구분자를 쓰는 것이다.
즉, 항목과 항목 사이에 구분자를 넣는 것. 위에서는 #을 썼다.
이름#전화번호#이메일주소 이런 식으로.
만약 존재하지 않는 항목의 경우 한개의 공백 문자로
이름# # 이메일주소 이런 식으로.

예를 들어, 지금까지와 같은 방식으로 해당 정보들을 저장하려면
이름 배열, 전화번호 배열, 이메일 주소 배열. .. 이런식으로 4개의 배열이 필요한데, 이것은 비효율적이다.
어떤 한 사람의 이름, 전화벊, 이메일 주소... 등은 항상 같이 붙어다녀야 한다. 그렇기 때문에, 이 경우, 구조체를 사용한다.
즉, 항상 같이 붙여다녀야 하는 데이터를 하나의 그룹으로 묶어주는 것이 구조체이다.

이렇게 한 사람의 정보를 구조체로 정의하고, 이것을 directory 한에 모든 사람의 정보를 각각 저장하는 것이다.

이제 read_line 의 용도는, 파일 까지 읽을 수 있다.

이와 같이, 파일에 저장되는 정보를 읽을 때, 라인 단위로 읽게 된다.
한 라인 단위로 읽는 이유는, 한 라인에, 한 사람의 정보가 읽는 것이니까.
이로 인해, int read_line( FILE *fp, char str[ ], int n)
에서, 첫번째 매개변수에 파일명을 추가하게 된 것이다.
FILe *fp 는, read_line 이 어떤 것을 읽는지를 알려주는 것이다. 특정 파일을 읽을 것인지, 사용자 입력으로부터 받을 것인지.
while( ( ch = fgetc( fp) ! = '\n' && ch ! = EOF )
지금까지는 파일에 있는 내용을 getchar 로 읽었다.
이번에는 fgetc 를 통해 읽는다.
fgetc( fp ) 를 하면, fp 로부터 한 글자를 읽는다.
'\n' 가 나올 때까지, 반복하면서, 읽은 char 를 str 배열에 넣는 것이다.
ch ! = EOF
파일의 중간은 '\n' 이 있기 때문에 그것이 나오기 전까지는 '\n'을 기준으로 읽을 수 있지만,
파일의 맨 마지막은 '\n' 이 없을 수도 있다.
그래서 ch ! = EOF 를 통해, 파일의 맨 마지막 줄. 에 도달할때까지라는 명령어를 추가해주는 것이다.
2. main


먼저, strcmp 함수를 통해서 이것이 add 인지, find 인지, 등을 비교한다.
argument = strtok( NULL , " " ) ;
그다음 token은 파일 이름이 될 것이다.
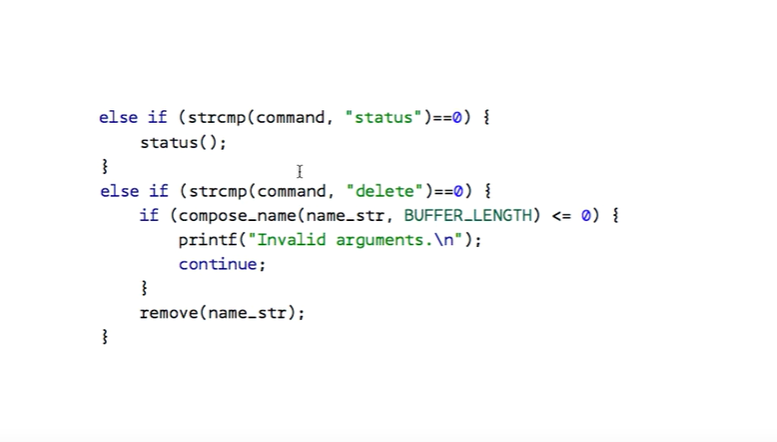


save 경우, 2번째 token 이 as 여야 한다.
as 가 아니라면 잘못된 것이고,
3번째 token은 파일 명
load

if( read_line ( fp, buffer, BUFFER_LENGTH) < = 0 ) : 더 이상 읽을 게 없으면, break
만일 유효한 정보가 있다면, name ~ group 정보를 읽고, 그 기준은 # 구분자를 기준으로 적용하는 것이다.
첫번째 ~ 4번째 token 이 각각 name ~ group 으로 들어가는 것이다.
기억할 것은, 존재하지 않는 항목은 한칸의 공백 문자이다.
이름이 없는 사람은 없으니, 해당 사항이 없지만,
number ~ group 같은 경우, 없을 수 있으므로,
그 경우에는 한 개의 공백 문자로 이루어진 string 이 되는 것이다.
그리고 다 읽게 되면, 그것을 add ( ) 를 통해 directory에 추가한다.
add

4개의 문자를 받는다.
그리고, 알파벳 순서대로, 이름을 저장하고,
그 위치에, 우리가 입력받은 한 사람의 4개의 정보를 구조체 한으로 넣는 것이다.
directory[ i +1 ] = directory [ i ] 라는 것은, 구조체도 = 를 통한 취합문이 가능하다는 것이다.
directory[ i +1 ]. number = strdup( number );
여기서 기억해야 할 것은, 만일 이 사람의 전화번호가 없다면, number 는 공백, 즉 1개의 공백 문자로 이루어진 string 이 된다.

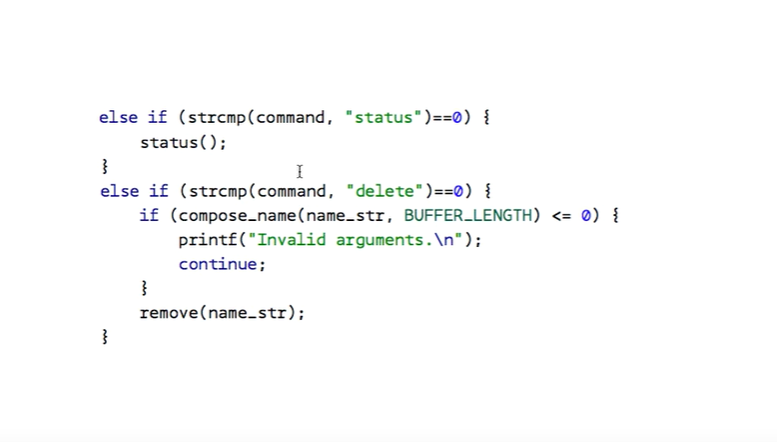

read 와 add 함수의 차이를 볼 필요가 있다.
read 의 경우에는, 뒤에 파일 이름이 나오고, 파일 이름에는 공백이 존재하지 않으므로, strtok 을 통해서 읽어낸다.
반면, add 뒤에는 4개의 정보가 나오고, 그 사이사이에 공백이 포함되거나, 각 정보안에 공백이 있을 수 있다. 그래서 strtok 이 아니라, 사용자 정의함수를 따로 만들어서, 정보를 읽어내야 한다.
ex. $ add Hong Gil-Dong 의 경우, 중간에 공백이 있는 사람의 이름을 압축해서, 불필요한 공백 버리고, !!!! 단어 사이에 여러개 공백은 1개의 공백으로 압축시켜서, 실제 저장할 때는
Hong Gil-Dong 이렇게 저장하자는 것이다.
compose_name 함수는 command_line 에서, 앞뒤에 붙은 불필요한 공백들을 제거하고, 단어와 단어 사이의 2개 사이의 공백이 있을 때, 그것을 하나의 공백으로 축약하는 것. name_str 이라는 이름으로 축약하기.
'C_Data Structure_Algorithm > C telephone v4.0' 카테고리의 다른 글
| C 전화번호부 v4.0_2) (0) | 2020.03.03 |
|---|
